
Perceptron: Multilingual, laughing, Pitfall-playing and streetwise AI
Research in the field of machine learning and AI, now a key technology in practically every industry and company, is far too voluminous for anyone to read it all. This column, Perceptron, aims to collect some of the most relevant recent discoveries and papers — particularly in, but not limited to, artificial intelligence — and explain why they matter.
Over the past few weeks, researchers at Google have demoed an AI system, PaLI, that can perform many tasks in over 100 languages. Elsewhere, a Berlin-based group launched a project called Source+ that’s designed as a way of allowing artists, including visual artists, musicians and writers, to opt into — and out of — allowing their work being used as training data for AI.
AI systems like OpenAI’s GPT-3 can generate fairly sensical text, or summarize existing text from the web, ebooks and other sources of information. But they’re historically been limited to a single language, limiting both their usefulness and reach.
Fortunately, in recent months, research into multilingual systems has accelerated — driven partly by community efforts like Hugging Face’s Bloom. In an attempt to leverage these advances in multilinguality, a Google team created PaLI, which was trained on both images and text to perform tasks like image captioning, object detection and optical character recognition.
Image Credits: Google
Google claims that PaLI can understand 109 languages and the relationships between words in those languages and images, enabling it to — for example — caption a picture of a postcard in French. While the work remains firmly in the research phases, the creators say that it illustrates the important interplay between language and images — and could establish a foundation for a commercial product down the line.
Speech is another aspect of language that AI is constantly improving in. Play.ht recently showed off a new text-to-speech model that puts a remarkable amount of emotion and range into its results. The clips it posted last week sound fantastic, though they are of course cherry-picked.
We generated a clip of our own using the intro to this article, and the results are still solid:
Exactly what this type of voice generation will be most useful for is still unclear. We’re not quite at the stage where they do whole books — or rather, they can, but it may not be anyone’s first choice yet. But as the quality rises, the applications multiply.
Mat Dryhurst and Holly Herndon — an academic and musician, respectively — have partnered with the organization Spawning to launch Source+, a standard they hope will bring attention to the issue of photo-generating AI systems created using artwork from artists who weren’t informed or asked permission. Source+, which doesn’t cost anything, aims to allow artists to disallow their work to be used for AI training purposes if they choose.
Image-generating systems like Stable Diffusion and DALL-E 2 were trained on billions of images scraped from the web to “learn” how to translate text prompts into art. Some of these images came from public art communities like ArtStation and DeviantArt — not necessarily with artists’ knowledge — and imbued the systems with the ability to mimic particular creators, including artists like Greg Rutowski.

Samples from Stable Diffusion.
Because of the systems’ knack for imitating art styles, some creators fear that they could threaten livelihoods. Source+ — while voluntary — could be a step toward giving artists greater say in how their art’s used, Dryhurst and Herndon say — assuming it’s adopted at scale (a big if).
Over at DeepMind, a research team is attempting to solve another longstanding problematic aspect of AI: its tendency to spew toxic and misleading information. Focusing on text, the team developed a chatbot called Sparrow that can answer common questions by searching the web using Google. Other cutting-edge systems like Google’s LaMDA can do the same, but DeepMind claims that Sparrow provides plausible, non-toxic answers to questions more often than its counterparts.
The trick was aligning the system with people’s expectations of it. DeepMind recruited people to use Sparrow and then had them provide feedback to train a model of how useful the answers were, showing participants multiple answers to the same question and asking them which answer they liked the most. The researchers also defined rules for Sparrow such as “don’t make threatening statements” and “don’t make hateful or insulting comments,” which they had participants impose on the system by trying to trick it into breaking the rules.
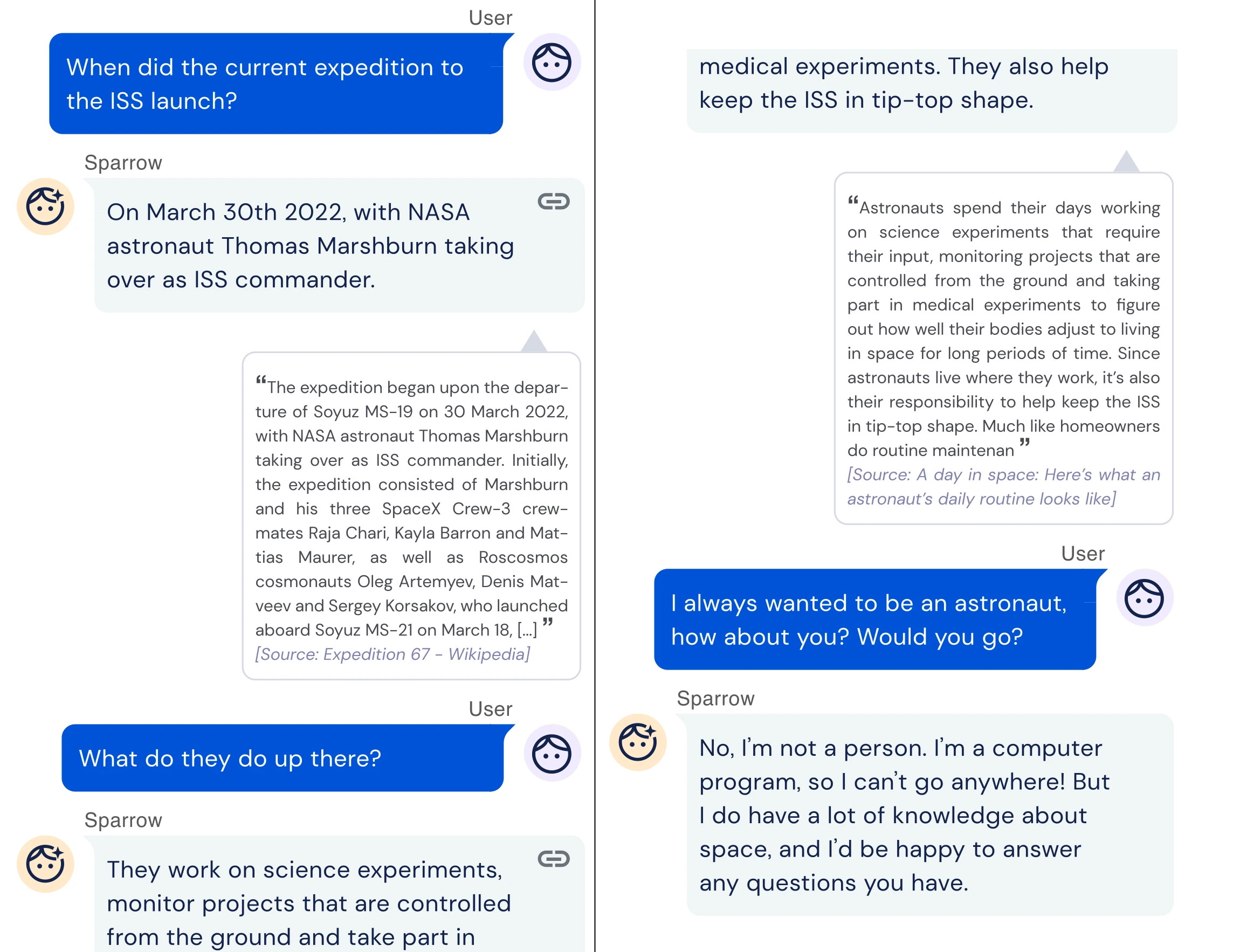
Example of DeepMind’s sparrow having a conversation.
DeepMind acknowledges that Sparrow has room for improvement. But in a study, the team found the chatbot provided a “plausible” answer supported with evidence 78% of the time when asked a factual question and only broke the aforementioned rules 8% of the time. That’s better than DeepMind’s original dialogue system, the researchers note, which broke the rules roughly three times more often when tricked into doing so.
A separate team at DeepMind tackled a very different domain recently: video games that historically have been tough for AI to master quickly. Their system, cheekily called MEME, reportedly achieved “human-level” performance on 57 different Atari games 200 times faster than the previous best system.
According to DeepMind’s paper detailing MEME, the system can learn to play games by observing roughly 390 million frames — “frames” referring to the still images that refresh very quickly to give the impression of motion. That might sound like a lot, but the previous state-of-the-art technique required 80 billion frames across the same number of Atari games.
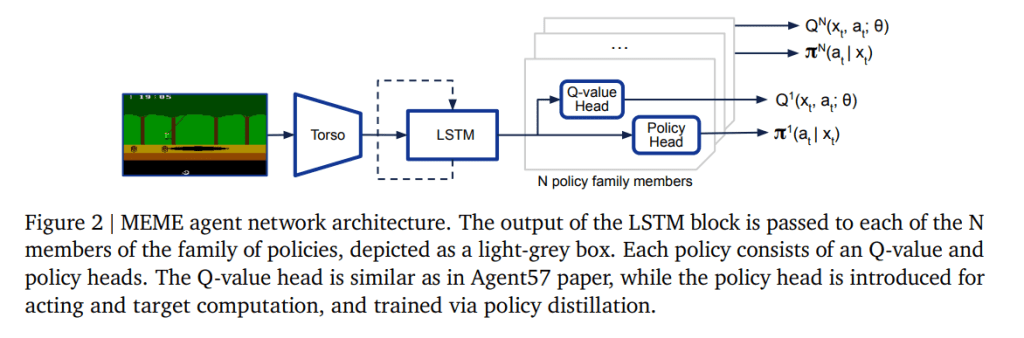
Image Credits: DeepMind
Deftly playing Atari might not sound like a desirable skill. And indeed, some critics argue games are a flawed AI benchmark because of their abstractness and relative simplicity. But research labs like DeepMind believe the approaches could be applied to other, more useful areas in the future, like robots that more efficiently learn to perform tasks by watching videos or self-improving, self-driving cars.
Nvidia had a field day on the 20th announcing dozens of products and services, among them several interesting AI efforts. Self-driving cars are one of the company’s foci, both powering the AI and training it. For the latter, simulators are crucial and it is likewise important that the virtual roads resemble real ones. They describe a new, improved content flow that accelerates bringing data collected by cameras and sensors on real cars into the digital realm.

A simulation environment built on real-world data.
Things like real-world vehicles and irregularities in the road or tree cover can be accurately reproduced, so the self-driving AI doesn’t learn in a sanitized version of the street. And it makes it possible to create larger and more variable simulation settings in general, which aids robustness. (Another image of it is up top.)
Nvidia also introduced its IGX system for autonomous platforms in industrial situations — human-machine collaboration like you might find on a factory floor. There’s no shortage of these, of course, but as the complexity of tasks and operating environments increases, the old methods don’t cut it any more and companies looking to improve their automation are looking at future-proofing.

Example of computer vision classifying objects and people on a factory floor.
“Proactive” and “predictive” safety are what IGX is intended to help with, which is to say catching safety issues before they cause outages or injuries. A bot may have its own emergency stop mechanism, but if a camera monitoring the area could tell it to divert before a forklift gets in its way, everything goes a little more smoothly. Exactly what company or software accomplishes this (and on what hardware, and how it all gets paid for) is still a work in progress, with the likes of Nvidia and startups like Veo Robotics feeling their way through.
Another interesting step forward was taken in Nvidia’s home turf of gaming. The company’s latest and greatest GPUs are built not just to push triangles and shaders, but to quickly accomplish AI-powered tasks like its own DLSS tech for uprezzing and adding frames.
The issue they’re trying to solve is that gaming engines are so demanding that generating more than 120 frames per second (to keep up with the latest monitors) while maintaining visual fidelity is a Herculean task even powerful GPUs can barely do. But DLSS is sort of like an intelligent frame blender that can increase the resolution of the source frame without aliasing or artifacts, so the game doesn’t have to push quite so many pixels.
In DLSS 3, Nvidia claims it can generate entire additional frames at a 1:1 ratio, so you could be rendering 60 frames naturally and the other 60 via AI. I can think of several reasons that might make things weird in a high performance gaming environment, but Nvidia is probably well aware of those. At any rate you’ll need to pay about a grand for the privilege of using the new system, since it will only run on RTX 40 series cards. But if graphical fidelity is your top priority, have at it.

Illustration of drones building in a remote area.
Last thing today is a drone-based 3D printing technique from Imperial College London that could be used for autonomous building processes sometime in the deep future. For now it’s definitely not practical for creating anything bigger than a trash can, but it’s still early days. Eventually they hope to make it more like the above, and it does look cool, but watch the video below to get your expectations straight.
Perceptron: Multilingual, laughing, Pitfall-playing and streetwise AI by Kyle Wiggers originally published on TechCrunch