
Google Deepmind trains a video game-playing AI to be your co-op companion
AI models that play games go back decades, but they generally specialize in one game and always play to win. Google DeepMind researchers have a different goal with their latest creation: a model that learned to play multiple 3D games like a human, but also does its best to understand and act on your verbal instructions.
There are of course “AI” or computer characters that can do this kind of thing, but they’re more like features of a game: NPCs that you can use formal in-game commands to indirectly control.
DeepMind’s SIMA (scalable instructable multiworld agent) doesn’t have any kind of access to the game’s internal code or rules; instead, it was trained on many, many hours of video showing gameplay by humans. From this data — and the annotations provided by data labelers — the model learns to associate certain visual representations of actions, objects and interactions. They also recorded videos of players instructing one another to do things in game.
For example, it might learn from how the pixels move in a certain pattern on screen that this is an action called “moving forward,” or when the character approaches a door-like object and uses the doorknob-looking object, that’s “opening” a “door.” Simple things like that, tasks or events that take a few seconds but are more than just pressing a key or identifying something.
The training videos were taken in multiple games, from Valheim to Goat Simulator 3, the developers of which were involved with and consenting to this use of their software. One of the main goals, the researchers said in a call with press, was to see whether training an AI to play one set of games makes it capable of playing others it hasn’t seen, a process called generalization.
The answer is yes, with caveats. AI agents trained on multiple games performed better on games they hadn’t been exposed to. But of course many games involve specific and unique mechanics or terms that will stymie the best-prepared AI. But there’s nothing stopping the model from learning those except a lack of training data.
This is partly because, although there is lots of in-game lingo, there really are only so many “verbs” players have that really affect the game world. Whether you’re assembling a lean-to, pitching a tent or summoning a magical shelter, you’re really “building a house,” right? So this map of several dozen primitives the agent currently recognizes is really interesting to peruse:
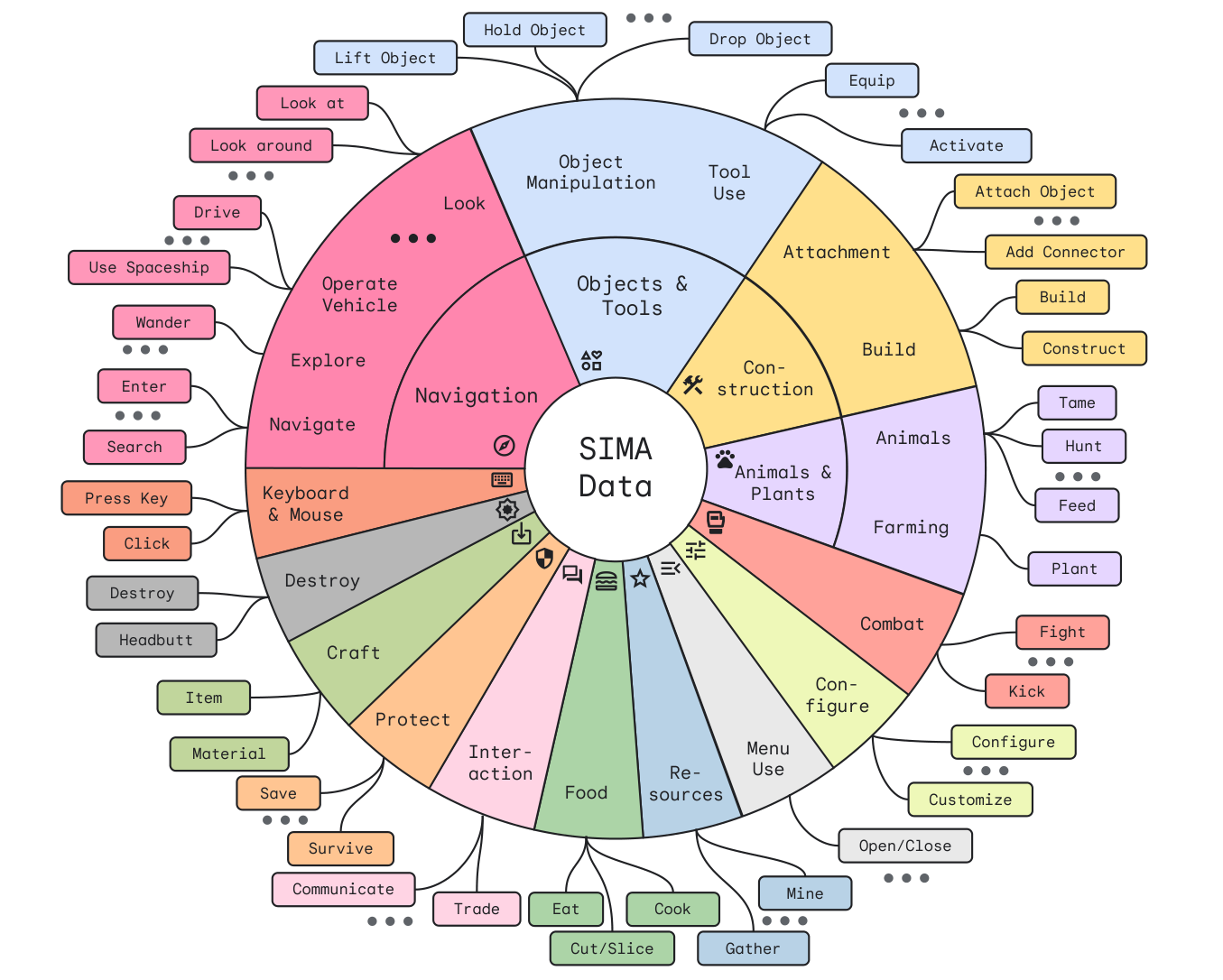
A map of several dozen actions SIMA recognizes and can perform or combine. Image Credits: Google DeepMind
The researchers’ ambition, on top of advancing the ball in agent-based AI fundamentally, is to create a more natural game-playing companion than the stiff, hard-coded ones we have today.
“Rather than having a superhuman agent you play against, you can have SIMA players beside you that are cooperative, that you can give instructions to,” said Tim Harley, one of the project’s leads.
Since when they’re playing, all they see is the pixels of the game screen, they have to learn how to do stuff in much the same way we do — but it also means they can adapt and produce emergent behaviors as well.
You may be curious how this stacks up against a common method of making agent-type AIs, the simulator approach, in which a mostly unsupervised model experiments wildly in a 3D simulated world running far faster than real time, allowing it to learn the rules intuitively and design behaviors around them without nearly as much annotation work.
“Traditional simulator-based agent training uses reinforcement learning for training, which requires the game or environment to provide a ‘reward’ signal for the agent to learn from — for example win/loss in the case of Go or Starcraft, or ‘score’ for Atari,” Harley told TechCrunch, and noted that this approach was used for those games and produced phenomenal results.
“In the games that we use, such as the commercial games from our partners,” he continued, “We do not have access to such a reward signal. Moreover, we are interested in agents that can do a wide variety of tasks described in open-ended text – it’s not feasible for each game to evaluate a ‘reward’ signal for each possible goal. Instead, we train agents using imitation learning from human behavior, given goals in text.”
In other words, having a strict reward structure can limit the agent in what it pursues, since if it is guided by score it will never attempt anything that does not maximize that value. But if it values something more abstract, like how close its action is to one it has observed working before, it can be trained to “want” to do almost anything as long as the training data represents it somehow.
Other companies are looking into this kind of open-ended collaboration and creation as well; conversations with NPCs are being looked at pretty hard as opportunities to put an LLM-type chatbot to work, for instance. And simple improvised actions or interactions are also being simulated and tracked by AI in some really interesting research into agents.
Of course there are also the experiments into infinite games like MarioGPT, but that’s another matter entirely.