
OctoAI wants to make private AI model deployments easier with OctoStack
OctoAI (formerly known as OctoML), announced the launch of OctoStack, its new end-to-end solution for deploying generative AI models in a company’s private cloud, be that on-premises or in a virtual private cloud from one of the major vendors, including AWS, Google, Microsoft and Azure, as well as CoreWeave, Lambda Labs, Snowflake and others.
In its early days, OctoAI focused almost exclusively on optimizing models to run more effectively. Based on the Apache TVM machine learning compiler framework, the company then launched its TVM-as-a-Service platform and, over time, expanded that into a fully fledged model-serving offering that combined its optimization chops with a DevOps platform. With the rise of generative AI, the team then launched the fully managed OctoAI platform to help its users serve and fine-tune existing models. OctoStack, at its core, is that OctoAI platform, but for private deployments.
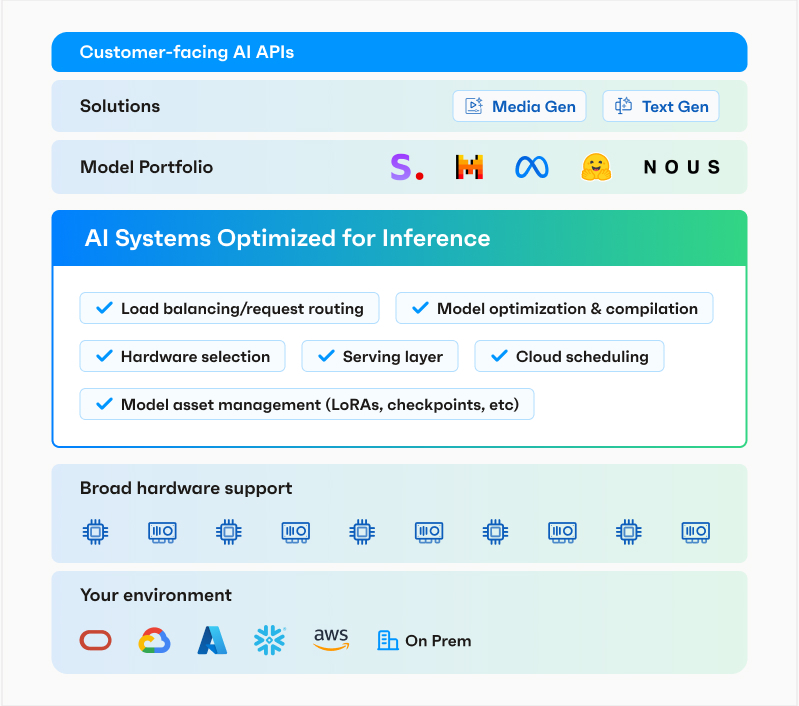
Image Credits: OctoAI
OctoAI CEO and co-founder Luis Ceze told me the company has over 25,000 developers on the platform and hundreds of paying customers who use it in production. A lot of these companies, Ceze said, are GenAI-native companies. The market of traditional enterprises wanting to adopt generative AI is significantly larger, though, so it’s maybe no surprise that OctoAI is now going after them as well with OctoStack.
“One thing that became clear is that, as the enterprise market is going from experimentation last year to deployments, one, all of them are looking around because they’re nervous about sending data over an API,” Ceze said. “Two: a lot of them have also committed their own compute, so why am I going to buy an API when I already have my own compute? And three, no matter what certifications you get and how big of a name you have, they feel like their AI is precious like their data and they don’t want to send it over. So there’s this really clear need in the enterprise to have the deployment under your control.”
Ceze noted that the team had been building out the architecture to offer both its SaaS and hosted platform for a while now. And while the SaaS platform is optimized for Nvidia hardware, OctoStack can support a far wider range of hardware, including AMD GPUs and AWS’s Inferentia accelerator, which in turn makes the optimization challenge quite a bit harder (while also playing to OctoAI’s strengths).
Deploying OctoStack should be straightforward for most enterprises, as OctoAI delivers the platform with read-to-go containers and their associated Helm charts for deployments. For developers, the API remains the same, no matter whether they are targeting the SaaS product or OctoAI in their private cloud.
The canonical enterprise use case remains using text summarization and RAG to allow users to chat with their internal documents, but some companies are also fine-tuning these models on their internal code bases to run their own code generation models (similar to what GitHub now offers to Copilot Enterprise users).
For many enterprises, being able to do that in a secure environment that is strictly under their control is what now enables them to put these technologies into production for their employees and customers.
“For our performance- and security-sensitive use case, it is imperative that the models which process calls data run in an environment that offers flexibility, scale and security,” said Dali Kaafar, founder and CEO at Apate AI. “OctoStack lets us easily and efficiently run the customized models we need, within environments that we choose, and deliver the scale our customers require.”