
Google’s new Gemini model can analyze an hour-long video — but few people can use it
Last October, a research paper published by a Google data scientist, the CTO of Databricks Matei Zaharia and UC Berkeley professor Pieter Abbeel posited a way to allow GenAI models — i.e. models along the lines of OpenAI’s GPT-4 and ChatGPT — to ingest far more data than was previously possible. In the study, the co-authors demonstrated that, by removing a major memory bottleneck for AI models, they could enable models to process millions of words as opposed to hundreds of thousands — the maximum of the most capable models at the time.
AI research moves fast, it seems.
Today, Google announced the release of Gemini 1.5 Pro, the newest member of its Gemini family of GenAI models. Designed to be a drop-in replacement for Gemini 1.0 Pro (which formerly went by “Gemini Pro 1.0” for reasons known only to Google’s labyrinthine marketing arm), Gemini 1.5 Pro is improved in a number of areas compared with its predecessor, perhaps most significantly in the amount of data that it can process.
Gemini 1.5 Pro can take in ~700,000 words, or ~30,000 lines of code — 35x the amount Gemini 1.0 Pro can handle. And — the model being multimodal — it’s not limited to text. Gemini 1.5 Pro can ingest up to 11 hours of audio or an hour of video in a variety of different languages.

Image Credits: Google
To be clear, that’s an upper bound.
The version of Gemini 1.5 Pro available to most developers and customers starting today (in a limited preview) can only process ~100,000 words at once. Google’s characterizing the large-data-input Gemini 1.5 Pro as “experimental,” allowing only developers approved as part of a private preview to pilot it via the company’s GenAI dev tool AI Studio. Several customers using Google’s Vertex AI platform also have access to the large-data-input Gemini 1.5 Pro — but not all.
Still, VP of research at Google DeepMind Oriol Vinyals heralded it as an achievement.
“When you interact with [GenAI] models, the information you’re inputting and outputting becomes the context, and the longer and more complex your questions and interactions are, the longer the context the model needs to be able to deal with gets,” Vinyals said during a press briefing. “We’ve unlocked long context in a pretty massive way.”
Big context
A model’s context, or context window, refers to input data (e.g. text) that the model considers before generating output (e.g. additional text). A simple question — “Who won the 2020 U.S. presidential election?” — can serve as context, as can a movie script, email or e-book.
Models with small context windows tend to “forget” the content of even very recent conversations, leading them to veer off topic — often in problematic ways. This isn’t necessarily so with models with large contexts. As an added upside, large-context models can better grasp the narrative flow of data they take in and generate more contextually rich responses — hypothetically, at least.
There have been other attempts at — and experiments on — models with atypically large context windows.
AI startup Magic claimed last summer to have developed a large language model (LLM) with a 5 million-token context window. Two papers in the past year detail model architectures ostensibly capable of scaling to a million tokens — and beyond. (“Tokens” are subdivided bits of raw data, like the syllables “fan,” “tas” and “tic” in the word “fantastic.”) And recently, a group of scientists hailing from Meta, MIT and Carnegie Mellon developed a technique that they say removes the constraint on model context window size altogether.
But Google is the first to make a model with a context window of this size commercially available, beating the previous leader Anthropic’s 200,000-token context window — if a private preview counts as commercially available.
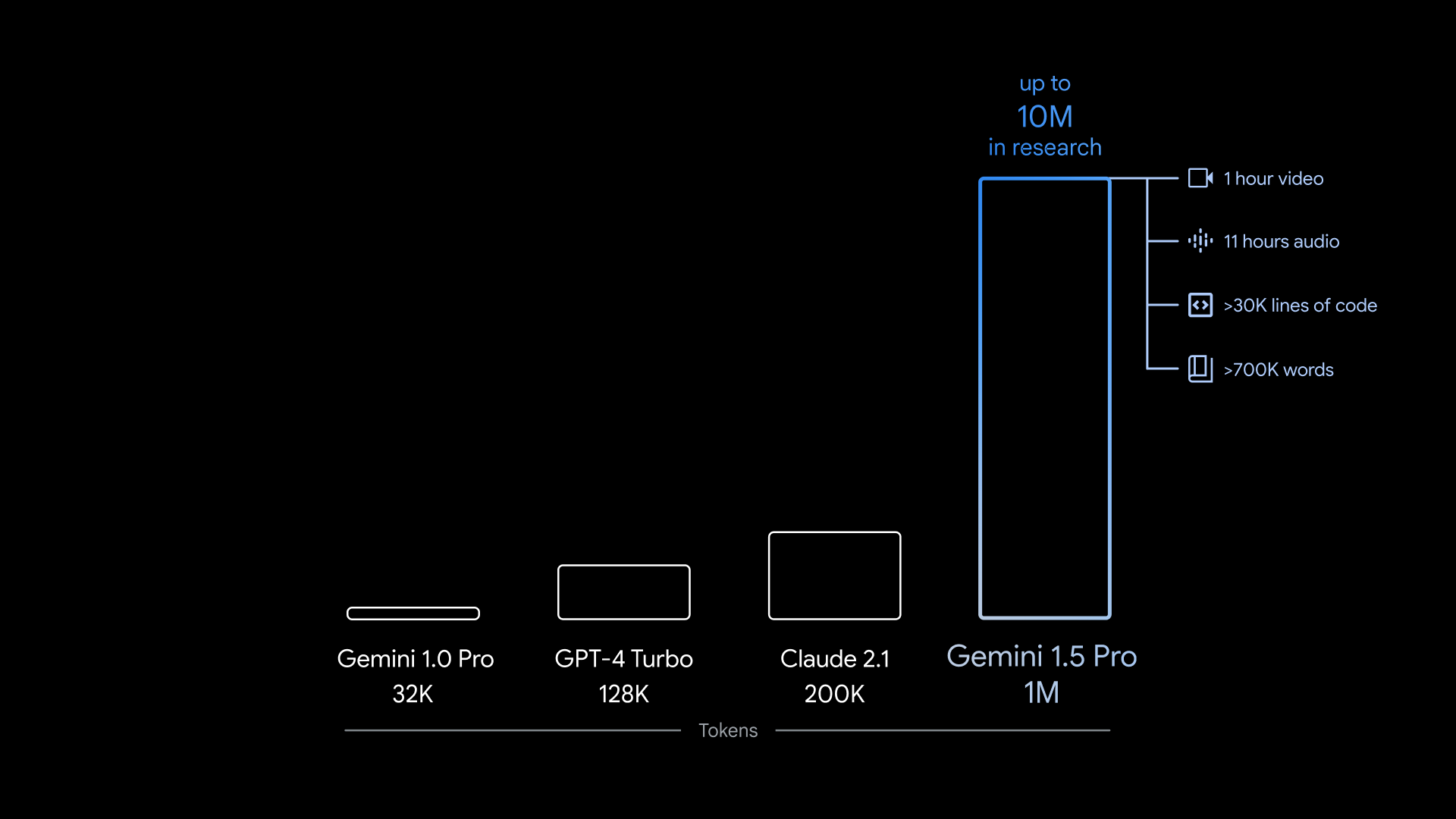
Image Credits: Google
Gemini 1.5 Pro’s maximum context window is 1 million tokens, and the version of the model more widely available has a 128,000-token context window, the same as OpenAI’s GPT-4 Turbo.
So what can one accomplish with a 1 million-token context window? Lots of things, Google promises — like analyzing a whole code library, “reasoning across” lengthy documents like contracts, holding long conversations with a chatbot and analyzing and comparing content in videos.
During the briefing, Google showed two prerecorded demos of Gemini 1.5 Pro with the 1 million-token context window enabled.
In the first, the demonstrator asked Gemini 1.5 Pro to search the transcript of the Apollo 11 moon landing telecast — which comes to around 402 pages — for quotes containing jokes, and then to find a scene in the telecast that looked similar to a pencil sketch. In the second, the demonstrator told the model to search for scenes in “Sherlock Jr.,” the Buster Keaton film, going by descriptions and another sketch.
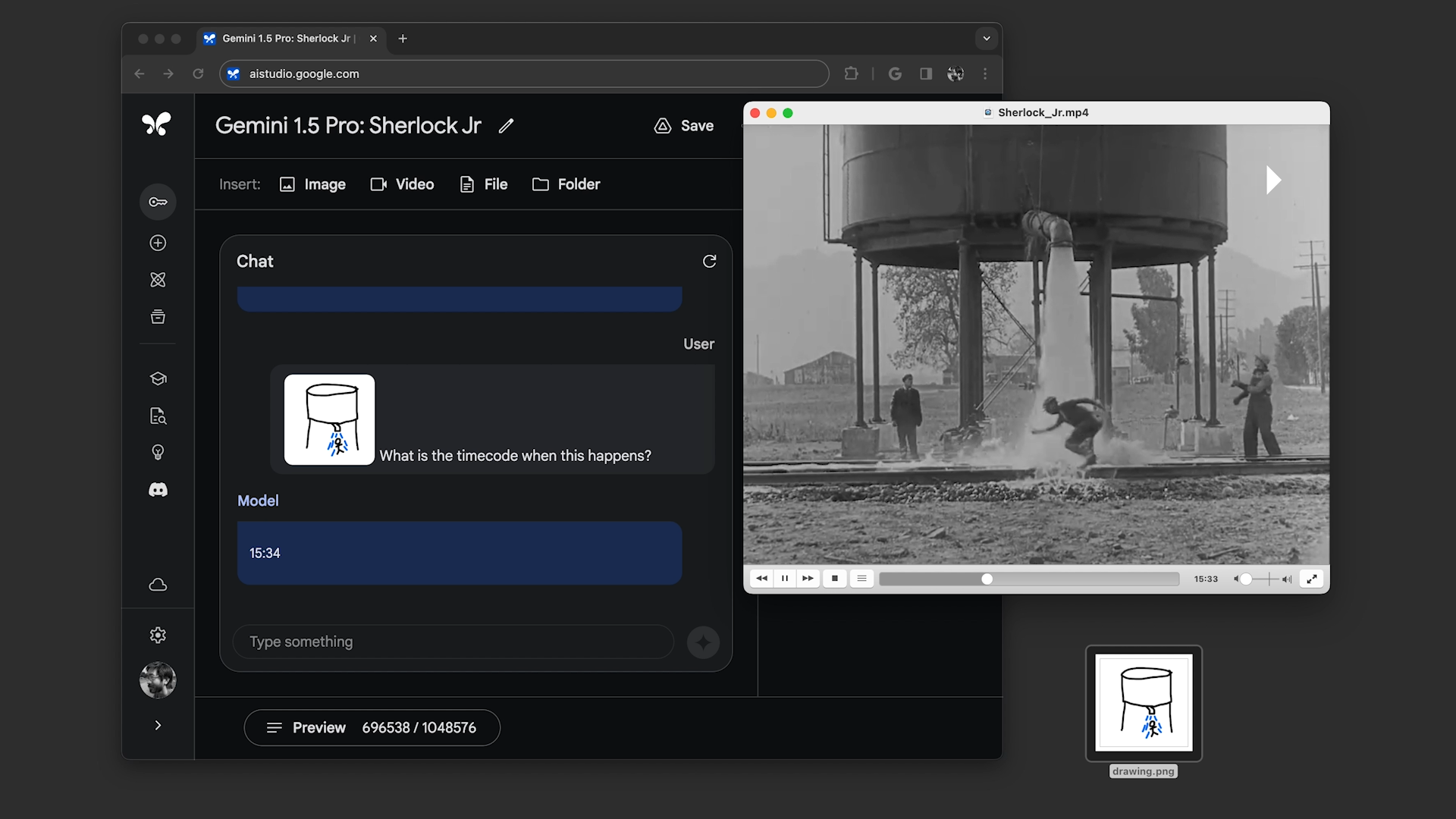
Image Credits: Google
Gemini 1.5 Pro successfully completed all the tasks asked of it, but not particularly quickly. Each took between ~20 seconds and a minute to process — far longer than, say, the average ChatGPT query.
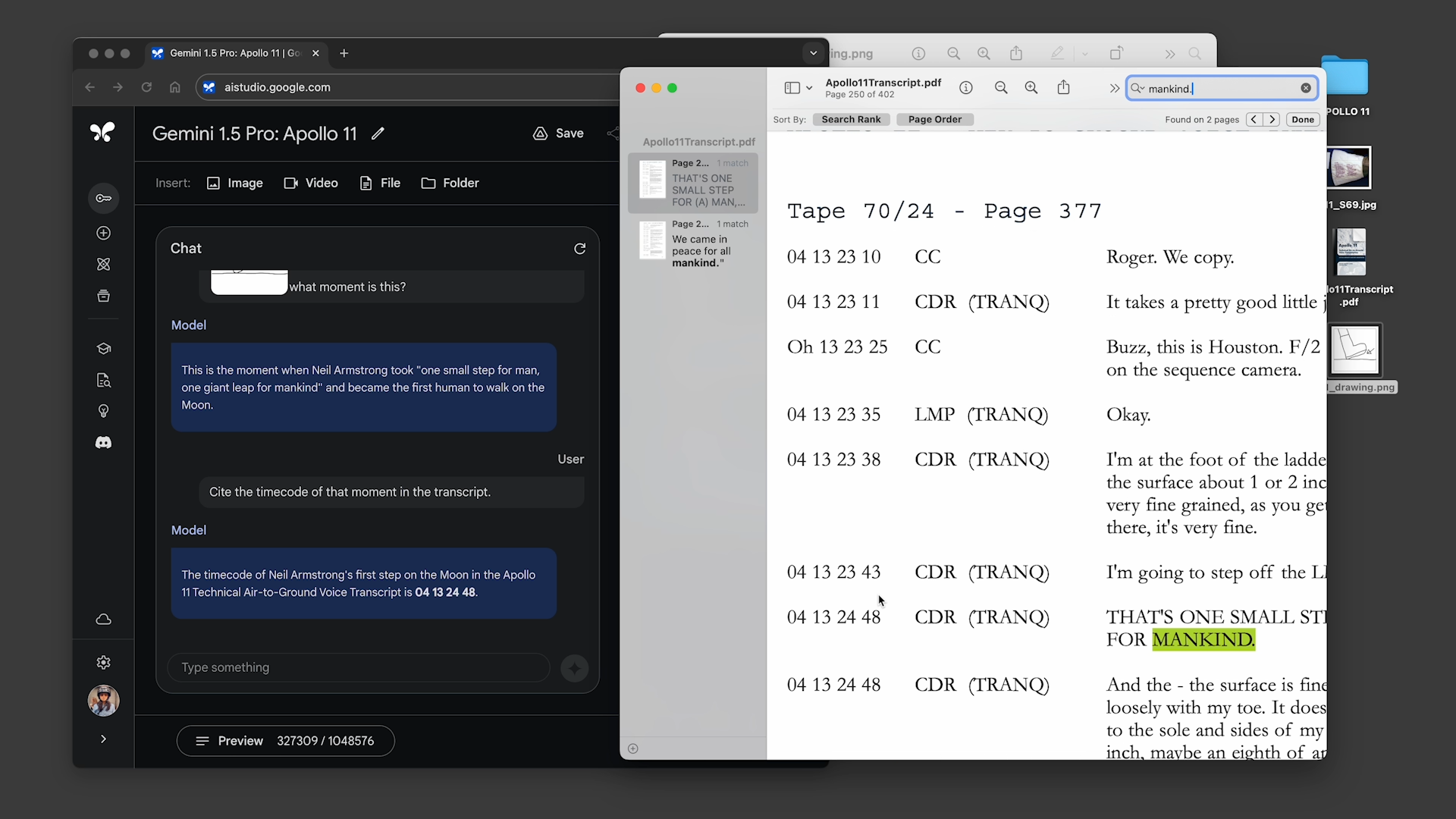
Image Credits: Google
Vinyals says that the latency will improve as the model’s optimized. Already, the company’s testing a version of Gemini 1.5 Pro with a 10 million-token context window.
“The latency aspect [is something] we’re … working to optimize — this is still in an experimental stage, in a research stage,” he said. “So these issues I would say are present like with any other model.”
Me, I’m not so sure latency that poor will be attractive to many folks — much less paying customers. Having to wait minutes at a time to search across a video doesn’t sound pleasant — or very scalable in the near term. And I’m concerned how the latency manifests in other applications, like chatbot conversations and analyzing codebases. Vinyals didn’t say — which doesn’t instill much confidence.
My more optimistic colleague Frederic Lardinois pointed out that the overall time savings might just make the thumb twiddling worth it. But I think it’ll depend very much on the use case. For picking out a show’s plot points? Perhaps not. But for finding the right screengrab from a movie scene you only hazily recall? Maybe.
Other improvements
Beyond the expanded context window, Gemini 1.5 Pro brings other, quality-of-life upgrades to the table.
Google’s claiming that — in terms of quality — Gemini 1.5 Pro is “comparable” to the current version of Gemini Ultra, Google’s flagship GenAI model, thanks to a new architecture comprised of smaller, specialized “expert” models. Gemini 1.5 Pro essentially breaks down tasks into multiple subtasks and then delegates them to the appropriate expert models, deciding which task to delegate based on its own predictions.
MoE isn’t novel — it’s been around in some form for years. But its efficiency and flexibility has made it an increasingly popular choice among model vendors (see: the model powering Microsoft’s language translation services).
Now, “comparable quality” is a bit of a nebulous descriptor. Quality where it concerns GenAI models, especially multimodal ones, is hard to quantify — doubly so when the models are gated behind private previews that exclude the press. For what it’s worth, Google claims that Gemini 1.5 Pro performs at a “broadly similar level” compared to Ultra on the benchmarks the company uses to develop LLMs while outperforming Gemini 1.0 Pro on 87% of those benchmarks. (I’ll note that outperforming Gemini 1.0 Pro is a low bar.)
Pricing is a big question mark.
During the private preview, Gemini 1.5 Pro with the 1 million-token context window will be free to use, Google says. But the company plans to introduce pricing tiers in the near future that start at the standard 128,000 context window and scale up to 1 million tokens.
I have to imagine the larger context window won’t come cheap — and Google didn’t allay fears by opting not to reveal pricing during the briefing. If pricing’s in line with Anthropic’s, it could cost $8 per million prompt tokens and $24 per million generated tokens. But perhaps it’ll be lower; stranger things have happened! We’ll have to wait and see.
I wonder, too, about the implications for the rest of the models in the Gemini family, chiefly Gemini Ultra. Can we expect Ultra model upgrades roughly aligned with Pro upgrades? Or will there always be — as there is now — an awkward period where the available Pro models are superior performance-wise to the Ultra models, which Google’s still marketing as the top of the line in its Gemini portfolio?
Chalk it up to teething issues if you’re feeling charitable. If you’re not, call it like it is: darn confusing.