
The takeaways from Stanford’s 386-page report on the state of AI
Writing a report on the state of AI must feel a lot like building on shifting sands: By the time you hit publish, the whole industry has changed under your feet. But there are still important trends and takeaways in Stanford’s 386-page bid to summarize this complex and fast-moving domain.
The AI Index, from the Institute for Human-Centered Artificial Intelligence, worked with experts from academia and private industry to collect information and predictions on the matter. As a yearly effort (and by the size of it, you can bet they’re already hard at work laying out the next one), this may not be the freshest take on AI, but these periodic broad surveys are important to keep one’s finger on the pulse of industry.
This year’s report includes “new analysis on foundation models, including their geopolitics and training costs, the environmental impact of AI systems, K-12 AI education, and public opinion trends in AI,” plus a look at policy in a hundred new countries.
Let us just bullet the highest-level takeaways:
- AI development has flipped over the last decade from academia-led to industry-led, by a large margin, and this shows no sign of changing.
- It’s becoming difficult to test models on traditional benchmarks and a new paradigm may be needed here.
- The energy footprint of AI training and use is becoming considerable, but we have yet to see how it may add efficiencies elsewhere.
- The number of “AI incidents and controversies” has increased by a factor of 26 since 2012, which actually seems a bit low.
- AI-related skills and job postings are increasing, but not as fast as you’d think.
- Policymakers, however, are falling over themselves trying to write a definitive AI bill, a fool’s errand if there ever was one.
- Investment has temporarily stalled, but that’s after an astronomic increase over the last decade.
- More than 70% of Chinese, Saudi, and Indian respondents felt AI had more benefits than drawbacks. Americans? 35%.
But the report goes into detail on many topics and subtopics and is quite readable and nontechnical. Only the dedicated will read all 386 pages of analysis, but really, just about any motivated body could.
Let’s look at Chapter 3, Technical AI Ethics, in a bit more detail.
Bias and toxicity are hard to reduce to metrics, but as far as we can define and test models for these things, it is clear that “unfiltered” models are much, much easier to lead into problematic territory. Instruction tuning, which is to say adding a layer of extra prep (such as a hidden prompt) or passing the model’s output through a second mediator model, is effective at improving this issue, but it’s far from perfect.
The increase in “AI incidents and controversies” alluded to in the bullets is best illustrated by this diagram:
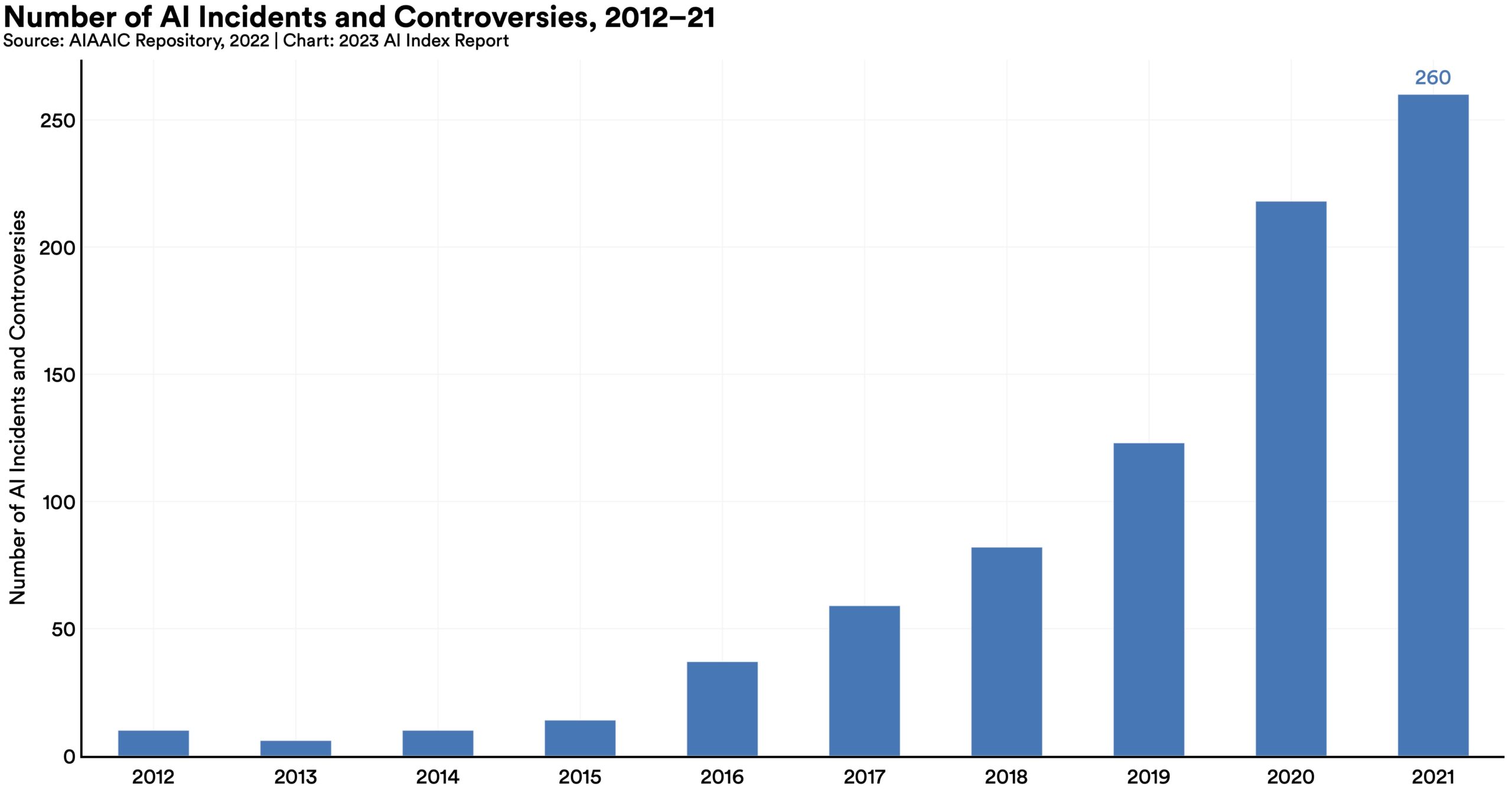
Image Credits: Stanford HAI
As you can see, the trend is upward and these numbers came before the mainstream adoption of ChatGPT and other large language models, not to mention the vast improvement in image generators. You can be sure that the 26x increase is just the start.
Making models more fair or unbiased in one way may have unexpected consequences in other metrics, as this diagram shows:
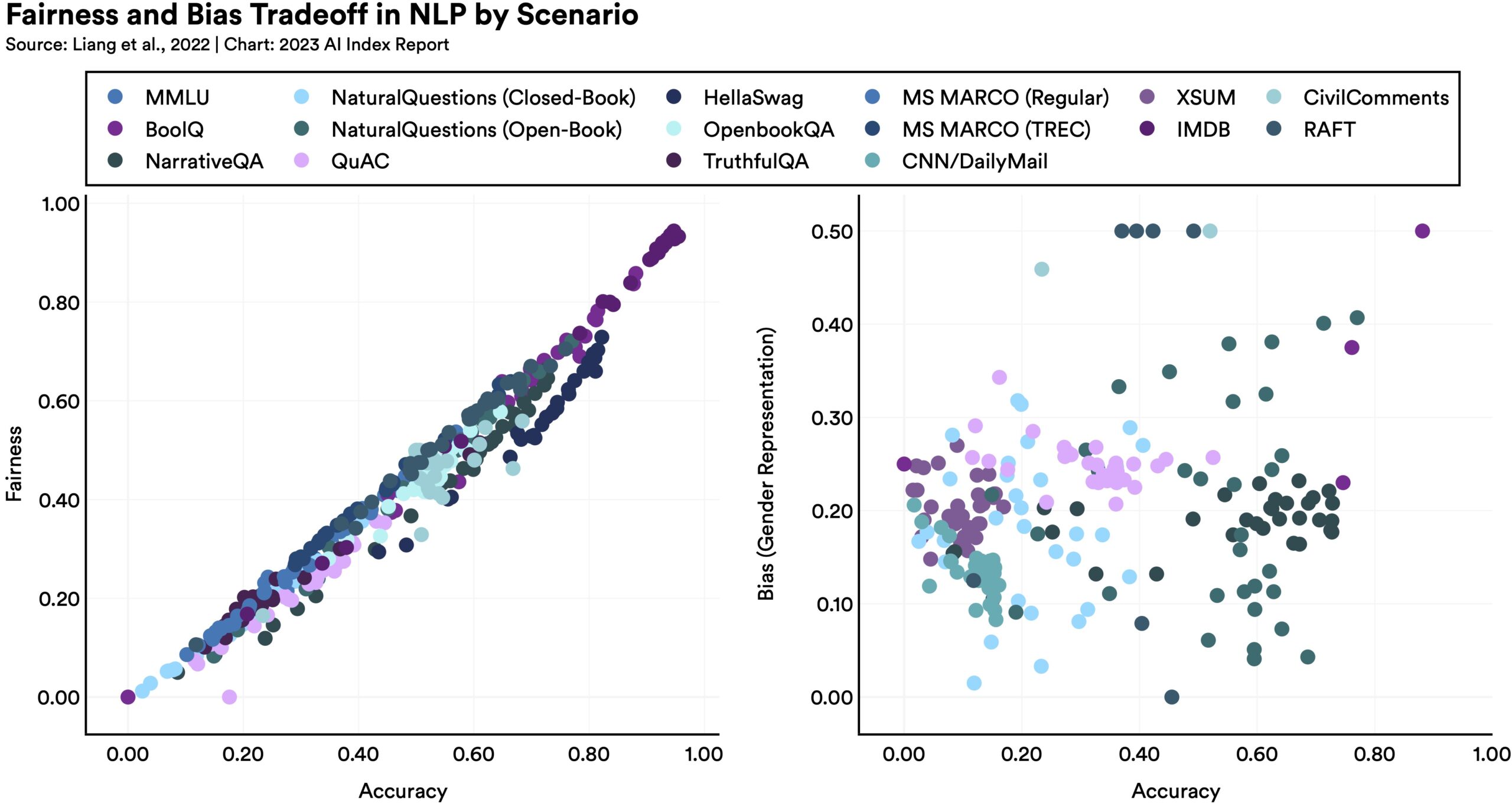
Image Credits: Stanford HAI
As the report notes, “Language models which perform better on certain fairness benchmarks tend to have worse gender bias.” Why? It’s hard to say, but it just goes to show that optimization is not as simple as everyone hopes. There is no simple solution to improving these large models, partly because we don’t really understand how they work.
Fact-checking is one of those domains that sounds like a natural fit for AI: Having indexed much of the web, it can evaluate statements and return a confidence that they are supported by truthful sources, and so on. This is very far from the case. AI actually is particularly bad at evaluating factuality and the risk is not so much that they will be unreliable checkers, but that they will themselves become powerful sources of convincing misinformation. A number of studies and datasets have been created to test and improve AI fact-checking, but so far we’re still more or less where we started.
Fortunately, there’s a large uptick in interest here, for the obvious reason that if people feel they can’t trust AI, the whole industry is set back. There’s been a tremendous increase in submissions at the ACM Conference on Fairness, Accountability, and Transparency, and at NeurIPS issues like fairness, privacy, and interpretability are getting more attention and stage time.
These highlights of highlights leave a lot of detail on the table. The HAI team has done a great job of organizing the content, however, and after perusing the high-level stuff here, you can download the full paper and get deeper into any topic that piques your interest.